ゲーム一般


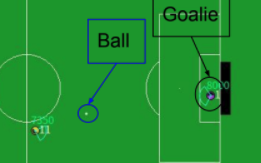
Half field offense RoboCup 2D Soccer (HFO) は RoboCup のシミュレーション環境の課題の一つで,強化学習の課題の一つです.
行動空間の階層性を適切に扱うため(turn 30 のようにパラメータ付き行動を扱うため),HA-PPOを提案しました.1:1での得点成功率約71%と強化学習手法では過去最高の成績を実現しました.
ゲームにおける強化学習を研究しています. 対象ゲームに関する人の知識や棋譜などを使わずに,ゲームのルール,あるいはシミュレータを通しての経験だけから学ぶことに挑戦があります.AlphaZeroも強化学習の応用と位置づけられます.
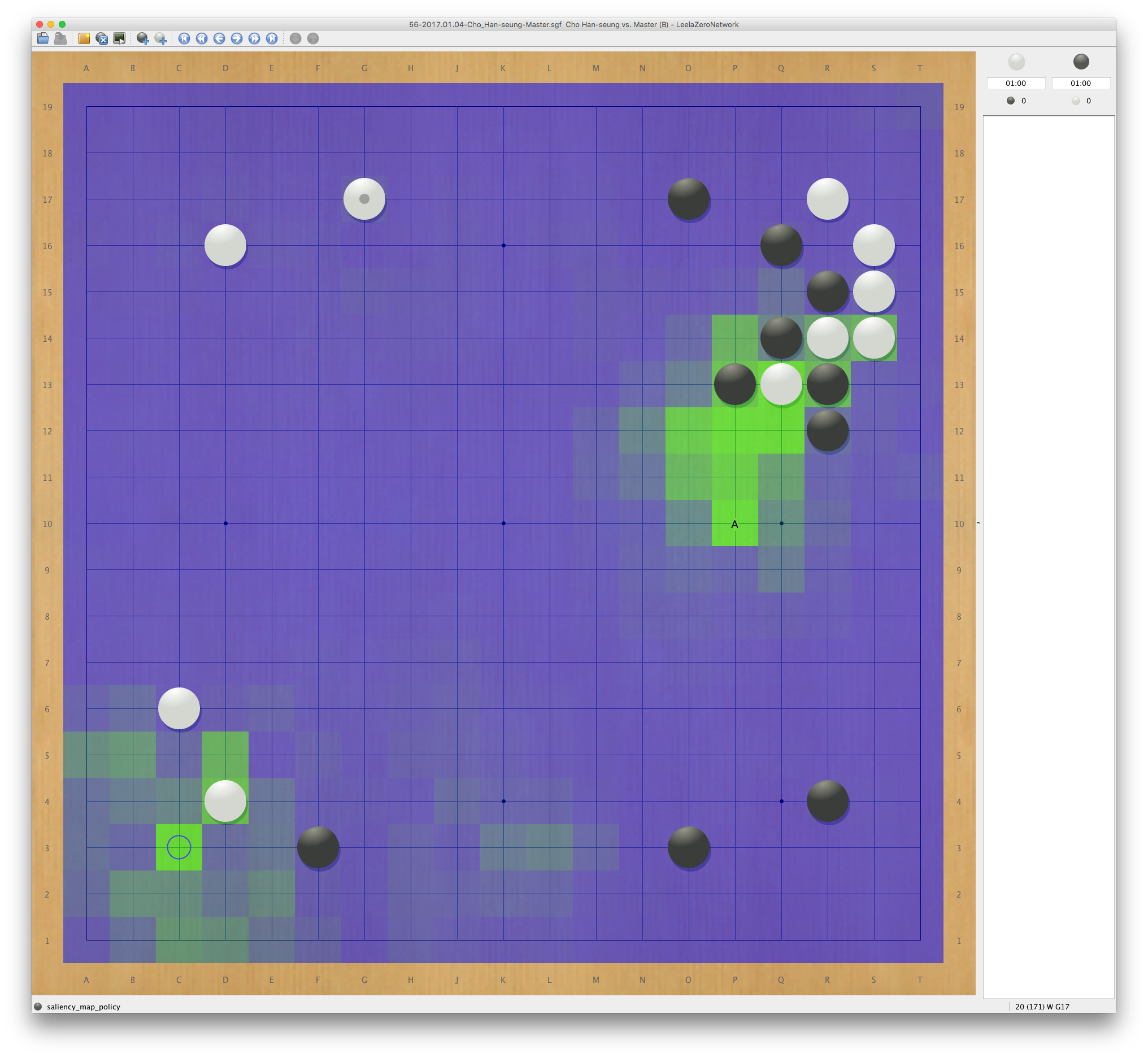
コンピュータ囲碁の研究を行っています
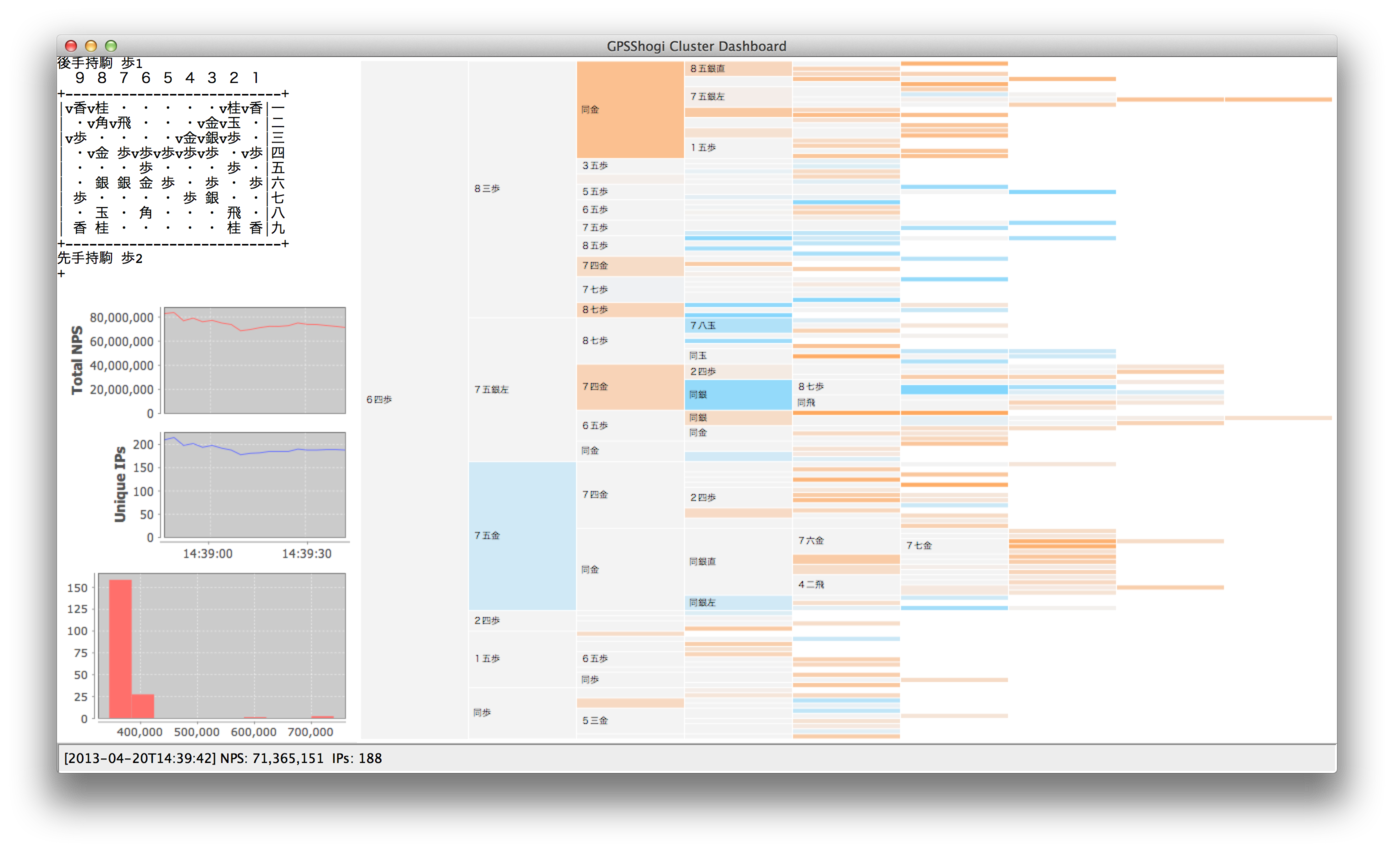
多数の計算機で協調して、効率よく探索する方法を研究しています。
モンテカルロ木探索の性能を改善する研究を、理論的な側面と実践的な側面の双方から行っています。
コンピュータ将棋の研究を行っています。
2013年4月にGPS将棋と三浦八段(当時,現九段)と対局が第二回電王戦第五局で行われました。
