
体験プロジェクト
学際科学科3年生向け 体験プロジェクト例
強化学習
AlphaZeroや様々な応用で注目されている強化学習について、基本的な手法を理解し、エージェントが試行錯誤を通じて賢くなる過程を小さな実験で観察しよう. たとえば、
- 有名アルゴリズムであるQ学習やSARSAについて,教科書 のCliff Walking (Example 6.6)を題材に再現実験を行う
- Open AI Gym の簡単な問題を学習させてみよう。たとえば、FrozenLake
| visit counts | policy |
|---|---|
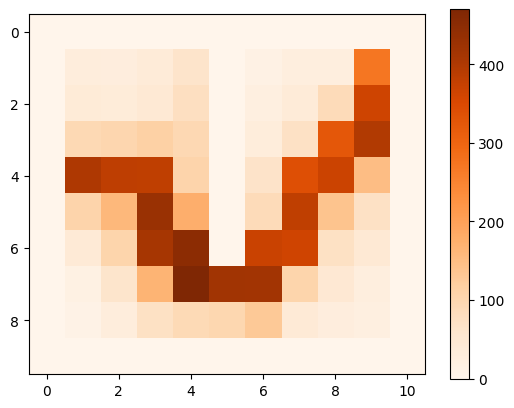
|
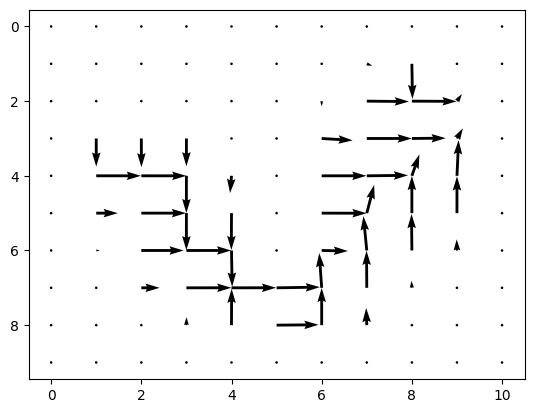
|
機械学習
機械学習の有名アルゴリズムを実装してみよう.たとえば
- EMアルゴリズムを教科書 PRMLの Figure 9.8 (第9章)を題材に再現実験を行い,理解を深めよう.
- VAE と VQ-VAE のモデルを理解し,簡単な実験をしてみよう.
original vae (1例) vqvae (1例) Fashion MNIST 


Cifar10 


グラフ描画
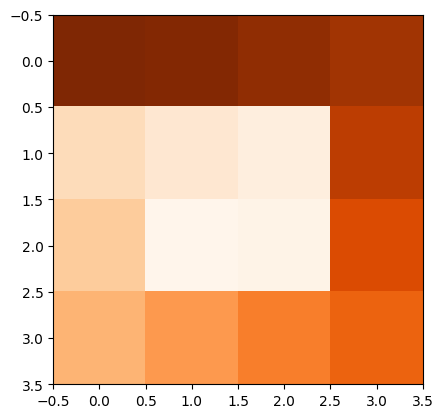
グラフの接続関係から定められる ラプラシアン は,ノードの数の正方行列で,その固有ベクトルは興味深い性質を持つ. たとえば2次元のグリッドマップで,左上から出発して時計回りに外から中心に向かって進めるような,幅1で実質前後のみ進めるというレイアウトを考える.その,最も小さい(自明なものを除いた)固有値の固有ベクトルを可視化すると,右図のように隣接するマスが近い値を持ちつつ,両端の差が最大となる.
様々なグラフについて,固有ベクトルを利用した可視化をしてみよう.
https://doi.org/10.1016/j.camwa.2004.08.015
Transformer
LLMs などの発展の基礎となった Transformer の encoder の部分をを,行列積や softmax などの部品から作ってみよう.
各 layer では,長さNのトークンの列を同じ長さのトークンの列に変換する.Encoder全体は,複数層の layer を積み重ねたもので, 全体として長さNのトークンの列を同じ長さのトークンの列に変換する. なお,長さNは,訓練時も実行時も可変である.
不完全情報ゲーム
近年急速に進歩した技術で、ポーカーなどで最善の戦略を計算するCounterfactual Regret Minimization (CFR)という手法を用いて、小さなゲームを解いてみよう。たとえば、じゃんけんやKuhn Pokerのナッシュ均衡になるべく近い近似戦略をもとめてみよう。
参考: An Introduction to Counterfactual Regret Minimization
モンテカルロ木探索
モンテカルロ木探索 (Monte-Carlo tree search; MCTS) を実装し,ゲーム木で性能を評価してみよう. ゲームの局面が ノード ,指し手が 辺 に,今考慮中の局面が 根 に対応する.MCTSは通常,根のみの状態から探索を始め,iteration 毎にノードを増やしながら各ノードの評価 (形勢判断) を正確にしてゆく.
- Python で将棋 miniosl の,ゲーム機能と訓練済みのニューラルネットワークを道具として使って,探索部分を作ってみよう

- C++でオープンソースライブラリのlibegoの囲碁盤機能を使って、ランダムな対局 (プレイアウト) から局面評価を行い MCTS (UCT) を組み合わせてみよう。プレイアウト部分はboard.RandomLightMove(random);を使うと便利。原始モンテカルロ法より強くなることを確認する。参考図書: コンピュータ囲碁 モンテカルロ法の理論と実践
shogi.go(50)value, moves = shogi.eval()

ゲームとデータからの学習
- 指手の確率の学習: 囲碁や将棋で、棋譜の指手を模倣するようなモデルを作成してみよう。予測精度を文献と比較したり、用いる棋譜との関係を検討する。 参考資料例: Computing Elo Ratings of Move Patterns in the Game of Go
- 評価関数の学習1: オセロの評価関数を探索結果を教師として最小二乗法で作成する。Logistelloの特徴 (feature) を使うと次元が100万程度まで大きくなるので、共役勾配法などを用いて効率よく計算する。
- 評価関数の学習2: Temporal Differenceと呼ばれる強化学習を行って、将棋の駒の強さなどを、対局から学ぶプログラムを作成する。
- 評価関数の学習3: Comparison Training (あるいはBonanza学習)の一部分を実装して、将棋の評価関数を学習させる。矢倉囲い、美濃囲いなどに組めることが目標。
- 評価関数の学習4: CNNを使って、ニューラルネットワークで勝敗を予測するモデルを訓練する
2048
2048の思考プログラムを作ってみよう。
グラフとA*探索
最短路問題などを解くために、幅優先探索、ダイクストラ法、A*探索を実装して性能を評価しよう。たとえば、4x4あるいは5x5のスライドパズルを解いてみよう。マンハッタン距離などヒューリスティックの効果を確認する。 (発展)disjoint pattern database (Korf 2002)を使ってさらなる性能向上を確認する。
参考図書: エージェントアプローチ人工知能 4章
多数決サーバとネットワーク/分散プログラミング
コンピュータ将棋のプロトコルであるUSIで将棋プログラム(たとえばgpsfish)を制御して、多数決で次の一手を決めるサーバプログラムを作成してみよう。多数決であればpythonなどスクリプト言語で十分だが。(発展)GPS将棋が行うような本格的な分散探索機能の追加を視野にいれる場合は,Go言語やC++ の方が適する。